こんにちは、DIGGLE エンジニアの3D沢庵です。決して三澤ではありません。
はじめてのアドベントカレンダー Advent Calendar 2023 の 24日目の記事です。
メリークリスマス!
はじめに
みなさんは Web セキュリティについて、どのようなイメージを持たれていますか?
サービスダウンや情報漏洩等、利用者としても運営者としても怖いものですね。
そんな Web セキュリティについて、2003年から数年おきに提供されている OWASP Top Ten というレポートについて少し調べてみた事をお話ししたいと思います。
脆弱性の変遷
ある時 OWASP Top Ten を眺めていると、ふと思いました。
昔のバージョンでも名前が違うけど似たような項目があったような‥‥と。
そこで、全バージョンを表にして、変遷を見やすくしてみましょう。
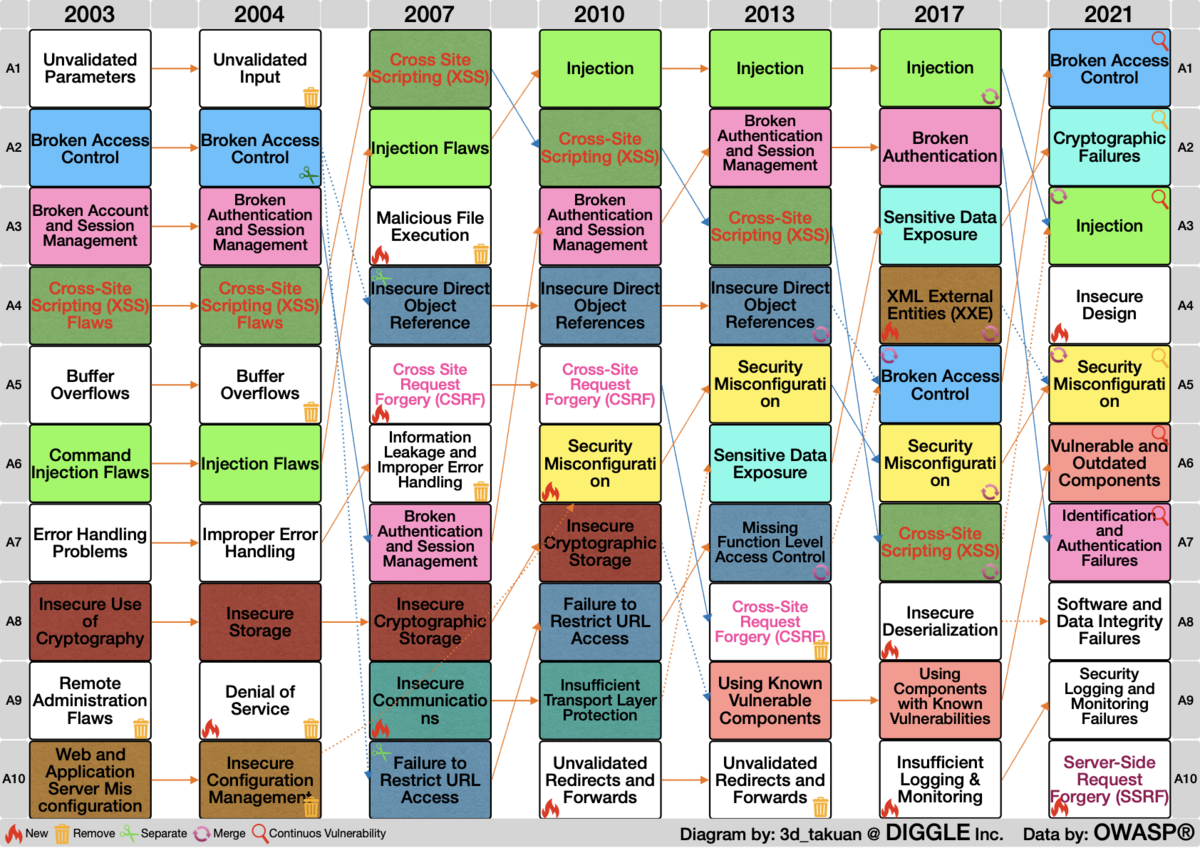
そうですね、あまり見やすくはないですね。
レイアウトの限界という事でどうぞご理解ください。
表の見方の簡単な説明は、以下のような感じです。
- 縦方向に上から下に1位〜10位、横方向に左から右に2003年版〜2021年版です。
- 版をまたいで同じ分類のものについて、項目の箱を同じ色にしています。
- 分割された項目や統合先と表記が乖離している項目は、同系統の暗めの色にしています。
- 左下に判例があるアイコンで、それぞれの項目に補足情報を付与しています。
 新設
新設 廃止
廃止 分割
分割 統合
統合 長くランクインし続けている項目 (この記事の焦点)
長くランクインし続けている項目 (この記事の焦点)
OWASP Top Ten は、2003年・2004年・2007年・2010年・2013年・2017年・2021年と、これまでに7回提供されています。
また、Mobile 向けや API 向けの Top Ten も別途提供されています。
それでは、Web 向けの最新版である2021年度版に基づいて、各脆弱性の変遷を見ていきたいと思います。
各項目名に OWASP の解説ページへのリンクを設定しているので、詳細はそちらをご参照ください。
脆弱性カウントダウン
第10位
変遷
| 入選 | 版数 | 年度 | 順位 | 名称 |
| 1. | #7 | 2021 | A10 | Server-Side Request Forgery (SSRF) |
第7版の2021年に新たに設けられた分類として10位にランクインしました。
発生数は比較的少ないものの被害が平均よりも大きくなりがちである事から、注意喚起の為にも選出されたようです。
第9位
変遷
| 入選 | 版数 | 年度 | 順位 | 名称 |
| 1. | #6 | 2017 | A10 | Insufficient Logging & Monitoring |
| 2. | #7 | 2021 | A09 | Security Logging and Monitoring Failures |
第6版の2017年に10位でランクインし、
2021年は9位に順位を上げています。
ロギングとモニタリングはテストが難しい上に、CVE / CVSS (*1) のような脆弱性情報として現れる事が少ないですが、うまく機能しなかった場合、説明責任やフォレンジック等影響が大きいです。このような点から選出されたようです。
*1: 分かり易さの為に CVE / CVSS の管理者では無く第三者の運営するサイトにリンクしています。
第8位
変遷
| 入選 | 版数 | 年度 | 順位 | 名称 |
| 1. | #6 | 2017 | A08 | Insecure Deserialization |
| 2. | #7 | 2021 | A08 | Software and Data Integrity Failures |
第6版の2017年に8位でランクインし、
2021年も8位でフィニッシュです。
CI/CD パイプラインで整合性未検証のデータを取り込んでしまう事により、必然的に脆弱性を作り込んでしまうという影響の大きさから選出されたようです。まるでスパイに潜入されてしまうようなイメージですね。対策としては、例えば SBOM の活用を検討する等が挙げられるのではないかと思います。もちろん OWASP が挙げている防止方法もチェックしたいですね。
第7位
変遷
| 入選 | 版数 | 年度 | 順位 | 名称 |
| 1. | #1 | 2003 | A03 | Broken Account and Session Management |
| 2. | #2 | 2004 | A03 | Broken Authentication and Session Management |
| 3. | #3 | 2007 | A07 | Broken Authentication and Session Management |
| 4. | #4 | 2010 | A03 | Broken Authentication and Session Management |
| 5. | #5 | 2013 | A02 | Broken Authentication and Session Management |
| 6. | #6 | 2017 | A02 | Broken Authentication |
| 7. | #7 | 2021 | A07 | Identification and Authentication Failures |
第1版の2003年に3位でランクインし、
2007年は7位に転落、
2010年はまた3位に返り咲き、
2013年からは2位まで上昇しましたが、
2021年はまたしても7位に転落しました。
以前は認証の不備としてカテゴライズされていた項目で、不適切な証明書の問題やセッション管理の問題も内包しています。本人確認が重要である事はオフラインの社会でも同じですね。継続的に選出されている事も納得できると思います。
第6位
変遷
| 入選 | 版数 | 年度 | 順位 | 名称 |
| 1. | #1 | 2003 | A08 | Insecure Use of Cryptography |
| 2. | #2 | 2004 | A08 | Insecure Storage |
| 3. | #3 | 2007 | A08 | Insecure Cryptographic Storage |
| 4. | #4 | 2010 | A07 | Insecure Cryptographic Storage |
| 5. | #5 | 2013 | A09 | Using Known Vulnerable Components |
| 6. | #6 | 2017 | A09 | Using Components with Known Vulnerabilities |
| 7. | #7 | 2021 | A06 | Vulnerable and Outdated Components |
第1版の2003年に8位でランクインし、
2010年に7位へ上昇しましたが、
2013年2017年と9位へ転落、
2021年過去最高位の6位に上昇しました。
簡潔に言うと、ライブラリ・ミドルウェア・ OS 等のバージョンを最新に保てていない問題です。現実問題として、隅々まで漏れなくアップデート済みかというと不安が残る方もいらっしゃるのではないでしょうか。そのような点から選出されたようですね。こちらについても SBOM や Vuls のようなツールが有用だと思われます。AWS の ECR もイメージスキャン機能を提供しているので、ぜひ活用したいですね。
第5位

変遷
| 入選 | 版数 | 年度 | 順位 | 名称 |
| 1. | #1 | 2003 | A10 | Web and Application Server Misconfiguration |
| 2. | #2 | 2004 | A10 | Insecure Configuration Management |
| 3. | #4 | 2010 | A06 | Security Misconfiguration |
| 4. | #5 | 2013 | A05 | Security Misconfiguration |
| 5. | #6 | 2017 | A06 | Security Misconfiguration |
| A04 | XML External Entities (XXE) | |||
| 6. | #7 | 2021 | A05 | Security Misconfiguration |
第1版の2003年に10位でランクインし、
2007年に一度ランク外になったにも関わらず、
2010年に再度6位にランクイン、
そこから5位と6位を行き来しており、
2021年は5位となっています。
統計的にアプリケーションの90%に何らかの設定ミスがあるとの事です。年々設定自体も複雑化していく事もあり、重要度が高い事から選出されたようです。
第4位
変遷
| 入選 | 版数 | 年度 | 順位 | 名称 |
| 1. | #7 | 2021 | A04 | Insecure Design |
第7版の2021年に新たに設けられた分類として4位にランクインしました。
設計やアーキテクチャの欠陥に関するリスクに焦点を当て、選出されたようです。 OWASP の概要において注目すべき CWE として、 CWE-209: エラーメッセージからの情報漏洩 や CWE-522: 適切に保護されていないクレデンシャル 等が挙げられています。他にも、ログにパスワード等が出力されている環境もまだまだあるのではないでしょうか。
第3位
変遷
| 入選 | 版数 | 年度 | 順位 | 名称 |
| 1. | #1 | 2003 | A04 | Cross-Site Scripting (XSS) Flaws |
| A06 | Command Injection Flaws | |||
| 2. | #2 | 2004 | A04 | Cross-Site Scripting (XSS) Flaws |
| A06 | Injection Flaws | |||
| 3. | #3 | 2007 | A01 | Cross Site Scripting (XSS) |
| A02 | Injection Flaws | |||
| 4. | #4 | 2010 | A01 | Injection |
| A02 | Cross-Site Scripting (XSS) | |||
| 5. | #5 | 2013 | A01 | Injection |
| A03 | Cross-Site Scripting (XSS) | |||
| 6. | #6 | 2017 | A01 | Injection |
| A07 | Cross-Site Scripting (XSS) | |||
| 7. | #7 | 2021 | A03 | Injection |
第1版の2003年に4位でランクインし、
2007年から2017年までの4回1位を独占し、
2021年は減速しながらも3位につけています。
統計的にアプリケーションの94%に何らかのインジェクションに関する問題があるとの事です。 SQL インジェクションや OS コマンドインジェクション等、何かしら一度は聞いた事があるかもしれません。選出は必然といったところではないかと思います。
第2位
変遷
| 入選 | 版数 | 年度 | 順位 | 名称 |
| 1. | #3 | 2007 | A09 | Insecure Communications |
| 2. | #4 | 2010 | A09 | Insufficient Transport Layer Protection |
| 3. | #5 | 2013 | A06 | Sensitive Data Exposure |
| 4. | #6 | 2017 | A03 | Sensitive Data Exposure |
| 5. | #7 | 2021 | A02 | Cryptographic Failures |
第3版の2007年に9位でランクインし、
2013年に6位へ躍進し、
2017年に3位、
2021年に2位と着実に順位を上げてきています。
機微情報の露出に直接的に関係する事や暗号化の不適切な設定や使用方法が散見される事等から選出されたようです。アリスとボブも納得ですね。
第1位
変遷
| 入選 | 版数 | 年度 | 順位 | 名称 |
| 1. | #1 | 2003 | A02 | Broken Access Control |
| 2. | #2 | 2004 | A02 | Broken Access Control |
| 3. | #3 | 2007 | A04 | Insecure Direct Object Reference |
| A10 | Failure to Restrict URL Access | |||
| 4. | #4 | 2010 | A04 | Insecure Direct Object Reference |
| A08 | Failure to Restrict URL Access | |||
| 5. | #5 | 2013 | A04 | Insecure Direct Object Reference |
| A07 | Failure to Restrict URL Access | |||
| 6. | #6 | 2017 | A05 | Broken Access Control |
| 7. | #7 | 2021 | A01 | Broken Access Control |
第1版の2003年に2位でランクインし、
2007年に2項目に分割された後、
2017年に再び統合され、
2021年にはとうとう念願(?)の1位を獲得しました。
統計的にアプリケーションの94%に何らかのアクセス制御の不備があるとの事です。一時期大きなニュースになっていたキャッシュサーバのトラブルに伴う情報漏洩やクロスサイトリクエストフォージェリ (CSRF) 等もこちらの項目に該当します。はまちちゃん、栄光の1位選出です!
まとめ
全10項目の内、過半数の6項目が長くランクインし続けていて、特に4項目は第1版の2003年から毎回ランクインしています。
2003年から2021年の間に、セキュリティに対する意識や組織的な取り組みは着実に向上してきているものと思われますが、バリデーションや設定・設計の不備等からくる脆弱性は残念ながら残り続けているようですね。
IaC や CI/CD 等により自動化された取り組みを積み上げていく事が、改善の道標だと考えられますが、2021年に8位となった項目で、 CI/CD の管理上の問題により脆弱性を抱えてしまうという問題に言及されている点も注目すべきだと思われます。
また、OWASP Top Ten はあくまでも分かりやすさを重視した形でのレポートだと思いますので、これだけやっておけば完璧というものではありませんが、まずは何に注意すべきかという意味ではとてもありがたい情報ですね。
身も蓋も無い結論ではありますが、結局はいかに確実に管理し続けられるかという問題に取り組みつつ、新しい脆弱性にも対応していくしかないようですね。
We're hiring!
予実管理の DIGGLE をより良くする為、リモートで一緒に開発しませんか?
「予実管理って何?」等少しでも興味をお持ち頂いたら、ぜひカジュアル面談しましょう!
私たち DIGGLE についてもっと知りたいと思って下さった方は以下をご覧ください。