こんにちは。 DIGGLE エンジニアの ito です。 九月末になり、厳しい残暑に少しずつ終わりが見え始めた中いかがお過ごしでしょうか?
ここ数年は、残暑という名だけで本格的な暑さが続いているように感じています。 私はDIGGLEエンジニアという身分の他に自前の田んぼでお米を育てている兼業農家という身分もあるため、毎年稲刈りの時期までこの厳しい残暑が続いてしまうと困るなと思っています。 ですが、今年も無事残暑が落ち着いてから稲刈りを実施することができて安心しました。
毎年稲を刈る度に新しいライブラリが現れるフロントエンド界隈ですが、最近の DIGGLE のフロントエンドでは従来 ContextAPI で行なっていた React の Global State 管理を見直し、移行先として有力な Recoil と Jotai を比較した上で Jotai を導入することに決定しました。 導入決定の経緯と導入する際の工夫について今回はお話しさせていただきます。
React の Global State 管理に関して
React ではアプリケーションの規模が大きくなるとしばしば Global State を導入することになると思います。 導入理由は、コンポーネントを細分化していくにあたってstate/props のバケツリレーの階層が深くなり可読性が落ちていくためなど様々だと思われますが、 DIGGLE でも例に漏れず可読性向上を目的として Global State を導入して管理を行ってきました。
DIGGLE では従来 Global State として ContextAPI を利用しており、
利用目的としては主に可読性向上だったため、Page コンポーネントなどの大元の親コンポーネントで Context を用意して子コンポーネントに伝播させていました。 (私の入社以前(2021年4月以前)には Redux を利用している時期もあったそうなのですが、ボイラープレートの管理が辛くメリットよりもデメリットが上回ったため ContextAPI に切り替えたとのことです)
上記のような使い方で可読性の向上をすることができたのですが、アプリケーションの成熟に伴って下記の問題が発生するようになりました。
- 無駄な再レンダリングの発生
- Context の肥大化
- Provider が乱立
特にDIGGLEでは大きな表を描画する必要があるなど、パフォーマンス向上が必須となる機能特性上、「無駄な再レンダリングの発生」を抑止するために、今回手を入れることになりました。
問題解決に向けた Recoil の検討
「無駄な再レンダリングの発生」は ContextAPI の使い方の問題ではあるものの元々の目的である可読性を落とさずに解決する方法は難しく、setState + ContextAPI の構成の移行先としてよく挙げられる Meta から公開されている Recoil を検討することにしました。
Recoil は 2020年5月に Meta によってリリースされた React 向けの状態管理ライブラリで、atom という単位で Global State 管理を行います。
atom はデータを入れるための箱のようなもので atom を定義すると箱が用意され、各種 getter や setter によってデータを出し入れできるようになります。
また、レンダリングするか否かはコンポーネントごとに使われている atom の値に変更があるかで実施されます。
| ContextAPI | Recoil | |
|---|---|---|
| 再レンダリングの判定 | Contextの値が変更されたら | atomの値が変更されたら |
| 再レンダリングの範囲 | Context.Providerで囲われた範囲 | atomの値が使われているコンポーネント |
Recoilを利用した例
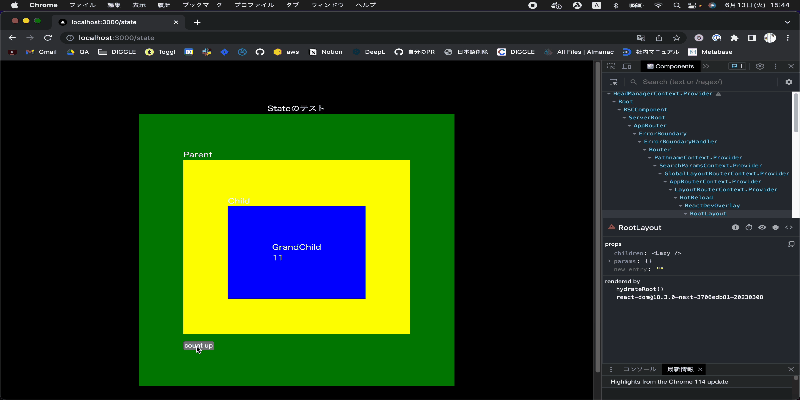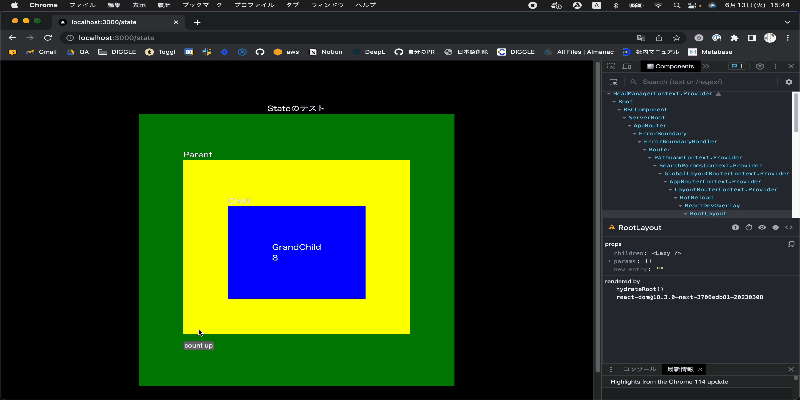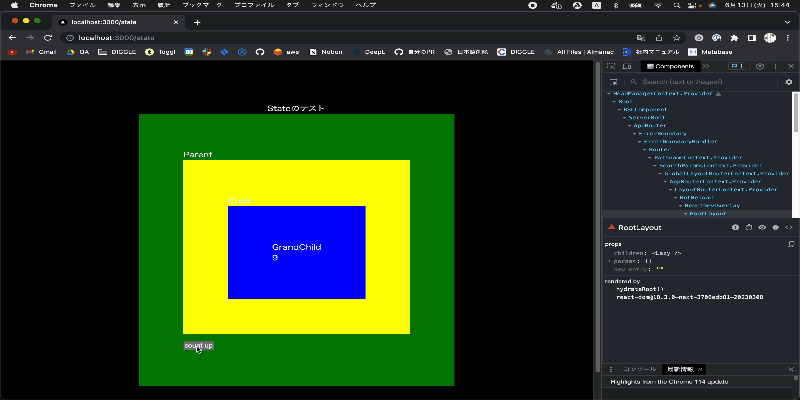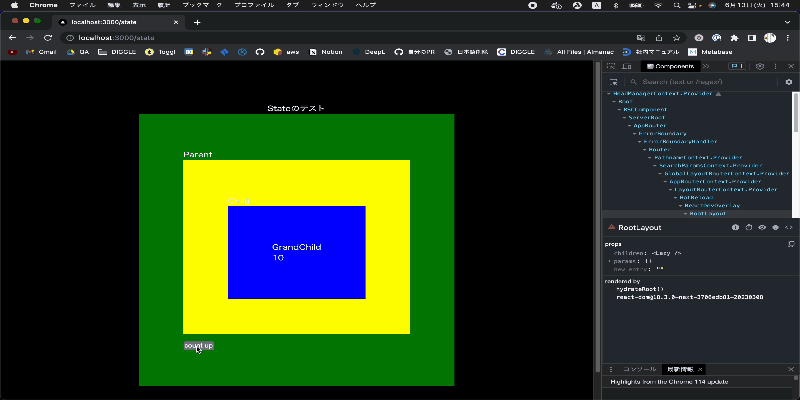
実際にRecoilを利用した場合で、どのように再描画が走るのかを確認したものが下記になります。

書いたコードは下記となっており、カウントをインクリメントするボタンを押してもuseRecoilValue を使っている GrandChildコンポーネントのみ再描画が走っていることがわかります。 また、ContextAPIと変わらず可読性高く記述ができることがわかります。
"use client" import React from 'react' import { RecoilRoot, useRecoilValue, useSetRecoilState } from 'recoil' import {hobbyAtomState} from "./atoms/HobbyAtom" const GrandChild = () => { const count = useRecoilValue(hobbyAtomState) return ( <div style={{backgroundColor: "blue", padding: "5rem"}}> <span> {count} </span> </div> ) } const Child = () => { return ( <div style={{backgroundColor: "yellow", padding: "5rem"}}> <GrandChild /> </div> ) } const Parent = () => { const setter = useSetRecoilState(hobbyAtomState) return ( <> <div style={{backgroundColor: "green", padding: "5rem"}}> <Child /> <button style={{marginTop: "1rem"}} onClick={()=>setter((count)=>count+1)}> count up </button> </div> </> ) } export default function RenderTest(){ return ( <RecoilRoot> <div>テスト</div> <Parent /> </RecoilRoot> ); };
一方で setState + ContextAPI を利用した場合では下記の図のようになり、カウントをインクリメントするボタンを押すとコンポーネント全体が再描画されていることがわかります。
上記検討で可読性を担保したまま再描画を抑えられることがわかったため Recoil での Global State 管理をおこなっていく方針で定めようと考えていました。 ですが、Recoil に懸念があることをある時メンバーから共有してもらったことで再度方針を考え直すことになります。
Recoil の懸念と Jotai の検討
Recoil で検討を進めていたところ DEV チームのメンバーから Recoil の開発継続性に対する不安があることを共有してもらいました。
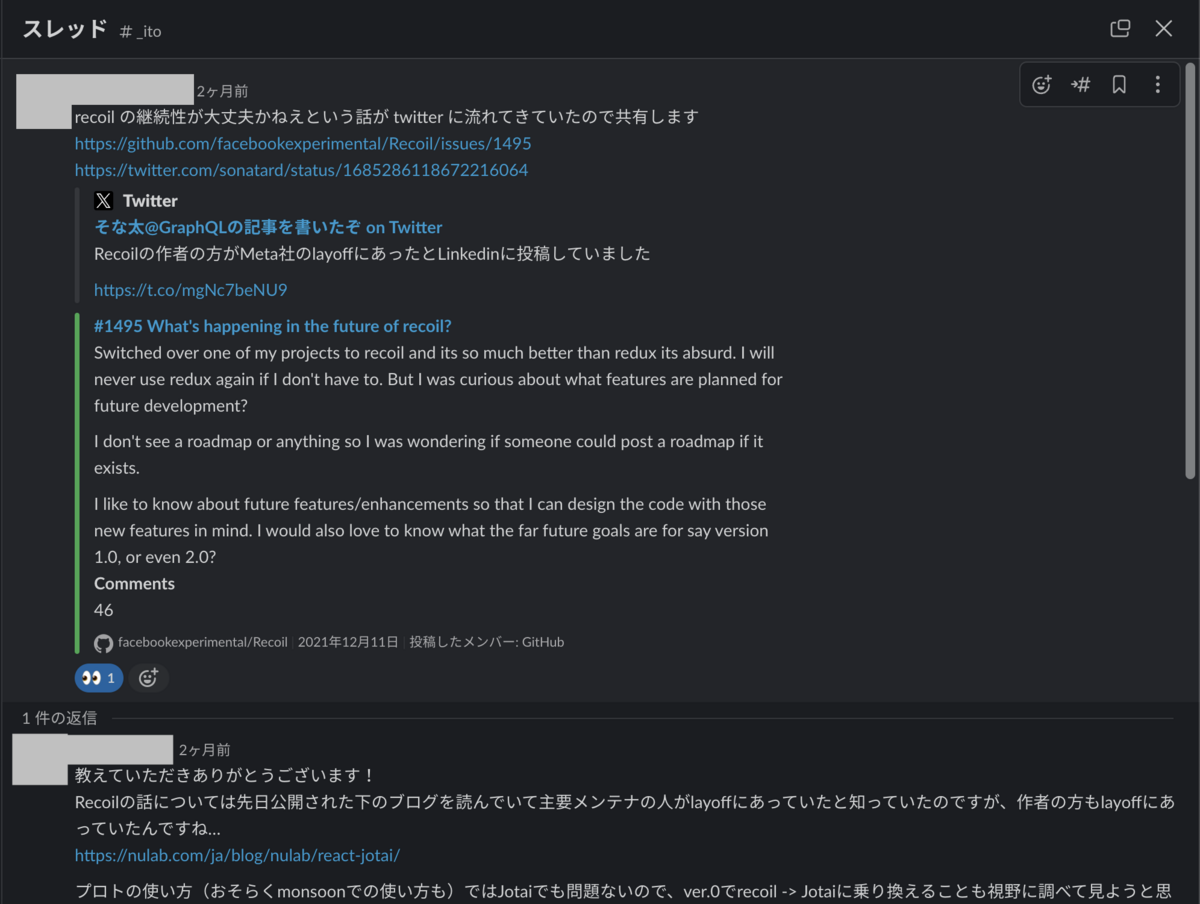
上記の issue を確認するとRecoil の主要メンテナがレイオフされたり、Jotai に切り替える方がいることがわかります。 Recoil が Meta社によって開発されいてるため優先して検討をしていたのですが、上記状況を踏まえると Meta社による開発という優位性が怪しいものとなったため、Jotai と比較検討することにしました。
結論からお伝えすると Jotai を採用したのですが、採用理由は主に下記になります。
- TypeScriptで開発されている
- 開発が活発
- callback 内などで atom を get する際に通常の atom の get と仕様が変わらない
TypeScriptで開発されている
Jotai は TypeSciprt で開発されているため、TypeScript で開発している DIGGLE のフロントエンドとも相性が良かったです。 型が細かく設定されており、型安全な状態で開発を進めることができました。
開発が活発
Recoil では先述の主要メンテナのレイオフであったり、major ver.の公開がされていないといった問題がありました。 Jotai は既に ver.2 が公開されており、月一以上でコンスタントに更新がされています。
callback 内などで atom を get する際に通常の atom の get と仕様が変わらない
Recoil にも Jotai にも useCallbackに似た hook が用意されています。
Recoil では useRecoilCallback であり、callback 内で atom の値を取得する際に snapshot と呼ばれるものを介して取得することになります。 最初に触った際にはここでも atom の時のように get で値を取得できれば嬉しいなと思っていました。
const logCartItems = useRecoilCallback(({snapshot}) => async () => { const numItemsInCart = await snapshot.getPromise(itemsInCart); console.log('Items in cart: ', numItemsInCart); }, []);
一方 Jotai では useAtomCallback であり、atom の値を取得する際には atom の getter 同様に get で取得できます。
const readCount = useAtomCallback( useCallback((get) => { const currCount = get(countAtom) setCount(currCount) return currCount }, []) )
似たような処理で同じような方法をとれることは可読性を上げ、実装する際には戸惑う可能性を減らすように感じました。 好みの問題ではあるのものの、上記の印象から私は Jotai の方が良さそうだと感じています。
Jotai への置き換えに関して
検討を通して Jotai を採用することに決めました。 すでに一部 Recoil で実装をしていた部分があったため、Recoil から Jotai への置き換えが発生しました。 ですが、 Recoil と Jotai には一部を除き仕様に大きな違いがなかったことや本格導入する前だったことから、置き換えの工数はそれほどかかりませんでした。
違いのあった点としては、リスト表示する複数の要素や大きなオブジェクト要素を atom で管理する方法です。
Recoil では atomFamily や selectorFamily といった collection の形でデータを保持するための Utils を用意しており、Recoil を導入した際には両方を使って処理を行なっていました。
import { atomFamily } from 'recoil'; import { Fact } from '@/models'; export const factsAtomState = atomFamily<Fact, number>({ key: 'atoms.factsAtom', default: new Fact(), });
一方 Jotai では atom の中に atom を入れるなど柔軟な表現が可能なため、 配列やオブジェクトを扱う際には、 atoms in atom パターンの利用が提案されていました。
import { atom, PrimitiveAtom } from 'jotai'; import { Fact } from '@/models'; type Facts = { [id: number]: PrimitiveAtom<Fact> }; export const factsAtom = atom<Facts>({});
そのため、置き換えの際に atomFamily や selectorFamily を Jotai 流の書き方に置き換えました。
また、Jotai では大きなオブジェクトを扱う際には focusAtom や splitAtom で分割するなどできます。 Recoil は atom の中に atom が入らないため、オブジェクトを細かく分割した atom を用意していたのですが、Jotai ではそれらをまとめて必要な単位で分割して切り出す形に変更しました。
import { atom } from 'recoil'; export const dateAtomState = atom<string>({ key: 'components.features.Fact.dateAtom', default: '', }); export const valueAtomState = atom<number>({ key: 'components.features.Fact.valueAtom', default: 0, });

import { atom } from 'jotai'; import { focusAtom } from 'jotai-optics'; type Fact = { date: string; value: number }; export const factAtom = atom<Fact>({ date: '', value: -1 }); export const dateAtom = focusAtom(factAtom, (optic) => optic.prop('date')); export const numberAtom = focusAtom(factAtom, (optic) => optic.prop('value'));

Jotai では手が届かない部分について
Jotai で気になった点として、 変数のスコープが複雑になりやすいという点があります。
Jotai では Atom を利用するコンポーネントを Provider で囲う必要があります。 ProviderはネストすることができるのですがそれぞれのProviderで独立してatomの値を管理することになり、useAtom などで何も指定せずに取得をすると取得コンポーネントがネストされている Provider の中で一番深いものから値をとってきます。つまり、Provider のネストによって atom のスコープが切られます。
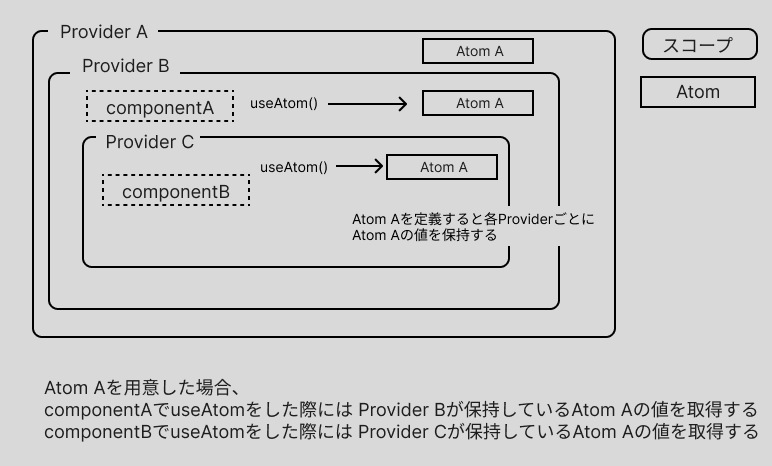
const RootComponent = () => ( <Provider> // Provider A <Provider> // Provider B <ComponentA /> <Provider> // Provider C <ComponentB /> </Provider> </Provider> </Provider> )
DIGGLEでは一覧ページから詳細ページへ遷移した場合や数値表現のプロパティを複数ページで使いまわしたいなど、ページを跨いだ変数のスコープが欲しくなる一方でパスパラメータやクエリパラメータの伝播などページごとに変数のスコープを切りたいものがありました。そのような場合でも一応狙ったProvider の値を取得する方法が Jotai には用意されており、 https://jotai.org/docs/guides/migrating-to-v2-api の Provider's scope prop の項目に方法が記述されています。
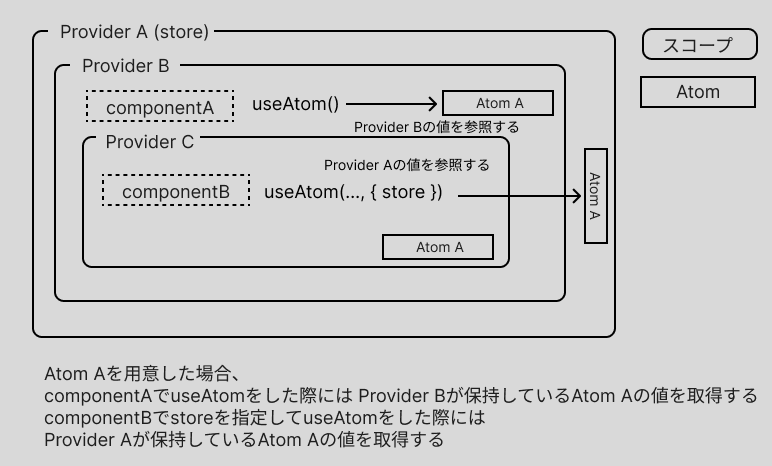
const MyContext = createContext() const store = createStore() // Parent component <MyContext.Provider value={store}> // Provider A <Provider> // Provider B <ComponentA /> <Provider> // Provider C <ComponentB /> </Provider> </Provider> </MyContext.Provider> // ComponentB Component const store = useContext(MyContext) useAtom(..., { store })
この方法では ContextAPI を使う必要があり、useAtom 時に使用する store を指定することから多用はしづらいように感じました。
現状変数のスコープを切って扱いたいものはパスパラメータやクエリパラメータに限定されていることもあり、どうせ ContextAPI を使う必要があるならと state を使わないことを前提に一部は従来のまま ContextAPI を利用することにしました。
そのため DIGGLE としては今後 Jotai / ContextAPI の組み合わせで使っていく方針としました。
まとめ
DIGGLEでは Jotai / ContextAPI の組み合わせを利用することに決定しました。 Jotai はシンプルでわかりやすく可読性とパフォーマンスを両立しながら今後の開発を行なっていけそうです。 基本的には Jotai を用いて Global State 管理を行い、state を使わずに変数のスコープを切って再利用したいものに関しては ContextAPI を利用していこうと思います。
今回は現時点での DIGGLE の環境において最善と思われる Global State 管理を検討したものになっており、結論は時期/環境によって大きく左右されると思います。 そのため Jotai は素晴らしいライブラリとは思うものの今回の決定に囚われることなく、その時々の状況に応じて適宜方針を検討し直していきたいと考えています。
今回は DIGGLE において Global State 管理を Jotai に決めた経緯を紹介させていただきました。 本記事が皆様の検討の際の一助になれば幸いです。
We're hiring!
予実管理の明日を切り開く為に日々精進している私達と一緒に開発してくれるメンバーを大募集です。
少しでも興味があれば、ぜひ下記採用サイトからエントリーください。